| 戻る |
p_getNth_b(,
n)の構文糖 (関数オブジェクトのみ) |
|
Public Function p__n(ByVal n As Long) As Variant |
|
|
|
printM_ mapF(p_a__o(p__n(0), p__n(1)),
Array(Array(1, 4), Array(4, 8), Array(8, 10))) |
|
1 2
3 |
|
4 5
6 7 |
|
8 9 |
|
|
IIf(pred(a), a', b')の構文糖 (関数オブジェクトのみ) |
|
Public Function p_try(ByRef pred As Variant, _ |
|
Optional ByRef f1 As Variant, Optional ByRef f2 As Variant) As Variant |
|
|
|
printM zipWith(p_try(p_less( ,6)) , iota(1,10), iota(21,30)) |
|
1 2
3 4 5
26 27 28 29 30 |
|

|
|
1 2 3 4 5
6 7 8 9 10
←第1引数の各要素が p_less(, 6) でチェックされる |
|
21 22 23 24 25 26 27 28 29 30 ←条件を満たさない場合は第2引数の各要素を選ぶ |
|
|
|
第1引数に対する変換を定義した場合 |
|
printM zipWith(p_try(p_less( ,6), p_mult(10)) , iota(1,10), iota(21,30)) |
|
10 20 30 40 50 26 27 28 29 30 |
|
第2引数に対する変換を定義した場合 |
|
printM zipWith(p_try(p_less( ,6), , p_mult(100)) , iota(1,10), iota(21,30)) |
|
1 2
3 4 5
2600 2700 2800 2900 3000 |
|
第1引数、第2引数ともに変換を定義した場合 |
| 戻る |
printM zipWith(p_try(p_less( ,6), p_mult(10),
p_mult(100)) , iota(1,10), iota(21,30)) |
|
10 20 30 40 50 2600 2700 2800 2900 3000 |
|
mapFなのでひとつの集合が対象 |
|
printM mapF(p_try(p_less( ,6), p_mult(-1)), iota(1,10)) |
|
-1 -2 -3 -4 -5 6
7 8 9
10 |
|
|
IIf(Not pred(a), a',
b')の構文糖 (関数オブジェクトのみ) |
|
Public Function p_try_not(ByRef pred As Variant, _ |
|
Optional ByRef f1 As Variant, Optional ByRef f2 As Variant) As Variant |
|
|
p_try(p_less(p__n(0), p__n(1)), p__n(0),
Null) の構文糖 (関数オブジェクトのみ) |
|
Public Function p_try_less() |
|
|
|
「first < second のときはfirstをとり、そうでなければNull値」 |
|
equal_range
の値を subV_if に代入するとき等に便利 |
|
seed_engine() |
|
a = uniform_int_dist(100, 0, 23)
← 0〜23の範囲の整数乱数100個 |
|
permutate a, sortindex(a)
← 昇順ソート |
|
er=mapF_swap(p_equal_range, a,
Array(2, 9, 11 ,13, 19, 20)) ←ジャグ配列 |
|
printM_ er |
|
13 16 |
|
39 47 |
|
56 57 |
|
64 64
← 範囲が[64, 64)なので、13に該当値なし |
|
76 79 |
|
79 84 |
|
printM subV_if(a, mapF(p_try_less,
er))
← 上記太字部分をとる(64のかわりにNull値) |
| 戻る |
2 9
11 19 20 |
|
|
データ型名 (関数オブジェクトのみ) |
|
Public Function p_typename( |
|
|
IsNumeric関数 (関数オブジェクトのみ) |
|
Public Function p_isNumeric( |
|
|
|
組み込みのIsNumeric関数より厳密に判定する |
|
Empty型と数値と見なせる文字列("123"等)は数値型ではみなさない |
|
|
Format関数 (関数オブジェクトのみ) |
|
Public Function p_format( |
|
|
InStr関数 (関数オブジェクトのみ) |
|
Public Function p_InStr( |
|
|
InStrRev関数 (関数オブジェクトのみ) |
| 戻る |
Public Function p_InStrRev( |
|
|
|
|
Like関数 (関数オブジェクトのみ) |
|
Public Function p_Like( |
|
|
StrConv関数 (関数オブジェクトのみ) |
|
Public Function p_StrConv( |
|
|
Trim関数 (関数オブジェクトのみ) |
|
Public Function p_Trim( |
|
p_Trim もしくは p_Trim(, 0)
' Trim |
|
p_Trim(, 1)
' LTrim |
|
p_Trim(,
-1)
' RTrim |
|
| 戻る |
|
|
文字列の左右分離 |
|
Function separate_string(ByRef expr As Variant, ByRef n As Variant) As Variant |
|
|
|
Function p_separate_string( |
|
|
|
printM separate_string("abcdefghij123456",
10) |
|
abcdefghij 123456 |
|
|
subM(m, 行範囲) の構文糖 |
|
Public Function subM_R(ByRef m As Variant, ByRef rRange As Variant) As Variant |
|
|
|
Public Function p_subM_R( |
|
|
subM(m, 行範囲) の構文糖(オフセットアドレス) |
|
Public Function subM_R_b(ByRef m As Variant, ByRef rRange As Variant) As Variant |
|
|
|
Public Function p_subM_R_b( |
|
| 戻る |
subM(m, , 列範囲) の構文糖 |
|
Public Function subM_C(ByRef m As Variant, ByRef cRange As Variant) As Variant |
|
|
|
Public Function p_subM_C( |
|
|
subM(m, , 列範囲) の構文糖(オフセットアドレス) |
|
Public Function subM_C_b(ByRef m As Variant, ByRef cRange As Variant) As Variant |
|
|
|
Public Function p_subM_C_b( |
|
|
特定行の取得(オフセットアドレス) |
|
index < 0 の場合は後ろから取得 |
|
Public Function selectRow_b(ByRef matrix As Variant, ByRef i As Variant) As Variant |
|
|
|
Public Function p_selectRow_b( |
|
| 戻る |
特定列の取得(オフセットアドレス) |
|
index < 0 の場合は後ろから取得 |
|
Public Function selectCol_b(ByRef matrix As Variant, ByRef j As Variant) As Variant |
|
|
|
Public Function p_selectCol_b( |
|
|
配列の特定行をデータで埋める(オフセットアドレス) |
|
Public Sub fillRow_b(ByRef matrix As Variant, ByVal i As Long, ByRef data As
Variant) |
|
|
配列の特定行をデータで埋めてmoveして返す(オフセットアドレス) |
|
Public Function fillRow_b_move(ByRef matrix As Variant, ByVal i As Long, ByRef data As
Variant) As Variant |
|
|
配列の特定列をデータで埋める(オフセットアドレス) |
|
Public Sub fillCol_b(ByRef matrix As Variant, ByVal j As Long, ByRef data As
Variant) |
|
|
配列の特定列をデータで埋めてmoveして返す(オフセットアドレス) |
|
Public Function fillCol_b_move(ByRef matrix As Variant, ByVal j As Long, ByRef data As
Variant) As Variant |
|
| 戻る |
|
|
1次元配列vecの隣接する要素間で2項操作opを行う |
|
出力列の要素数は元の要素数 - 1 (LBound = 0) |
|
Public Function adjacent_op(ByRef op As Variant, ByRef vec As Variant) As Variant |
|
|
|
Public Function p_adjacent_op( |
|
|
|
printM adjacent_op(p_plus, iota(1,10)) |
|
3 5
7 9 11 13 15 17 19 ← 1+2,
2+3, ・・・ , 9 + 10 |
|
|
1次元配列の重複要素を削除する (ソート済前提、compは等値条件) |
|
Public Function get_unique(ByRef vec As Variant,
Optional ByRef comp As Variant) As Variant |
|
|
|
Public Function p_get_unique( |
|
|
2次元配列の行ごとに関数適用 |
|
Public Sub rowWise_change(ByRef matrix As Variant, ByRef funcs As Variant) |
|
|
2次元配列の行ごとに関数適用しmoveして返す |
|
Public Function rowWise_change_move(ByRef matrix As Variant, ByRef funcs As Variant) As Variant |
| 戻る |
|
|
Public Function p_rowWise_change_move( |
|
|
2次元配列の列ごとに関数適用 |
|
Public Sub columnWise_change(ByRef matrix As Variant, ByRef funcs As Variant) |
|
|
2次元配列の列ごとに関数適用しmoveして返す |
|
Public Function columnWise_change_move(ByRef matrix As Variant, ByRef funcs As Variant) As Variant |
|
|
|
Public Function p_columnWise_change_move( |
|
|
1次元配列の全要素の等値比較 |
|
Public Function equal_all(ByRef a As Variant, ByRef b As Variant) As Variant |
|
|
|
Public Function p_equal_all( |
|
|
1次元配列の全要素の等値比較(述語バージョン) |
|
Public Function equal_all_pred(ByRef pred As Variant, ByRef a As Variant, ByRef b As Variant)
As Variant |
|
| 戻る |
|
|
述語を与えて1次元配列をフィルタリング |
|
Public Function filter_if(ByRef fun As Variant, ByRef vec As Variant) As Variant |
|
|
|
printM filter_if(p_less(,
10), iota(1, 20)) |
|
1 2
3 4 5
6 7 8
9 |
|
|
述語を与えて1次元配列をフィルタリング(否定形) |
|
Public Function filter_if_not(ByRef fun As Variant, ByRef vec As Variant) As Variant |
|
|
|
printM filter_if_not(p_less(, 10), iota(1, 20)) |
|
10 11 12 13 14 15 16 17 18 19 20 |
|
|
論理Not (関数オブジェクトのみ)(0, Null, Empty, Nothing,
CDate(0) はFalseとみなす) |
|
Public Function p_Not( |
|
|
含意(A=>B) IIF(Not A Or B, True,
False) (関数オブジェクトのみ) |
|
Public Function p_imply( |
|
|
vh_pipeオブジェクトの生成 |
| 戻る |
Public Function pipe(ByRef x As Variant) As vh_pipe |
|
|
|
? pipe(3) _ |
|
.→(p_plus(10)) _ |
|
.→(p_mult(10)) _ |
|
.→(p_minus(, 3))
_ |
|
.val |
|
127
<-
((3 + 10) * 10) - 3 |
|
|
vh_pipeオブジェクトの生成(引数をmoveする) |
|
Public Function pipe_(ByRef x As Variant) As vh_pipe |
|
|
|
printM pipe_(iota(1,
20)) _ |
|
.→(p_filter_if(p_less(yield_1, 10))) _ |
|
.→(p_mapF(p_mult(yield_1, 100))) _ |
|
.pop |
|
100 200 300 400 500 600 700 800 900 |
|
|
vh_stdvecオブジェクトの生成 |
| 戻る |
Public Function stdVec(Optional ByRef x As Variant) As vh_stdvec |
|
|
|
set x = stdVec(iota(1,10)) |
|
x.push_back(31) |
|
x.printM |
|
1 2
3 4 5
6 7 8
9 10 31 |
|
|
delimiterで区切られた文字列を関数列へマッピング |
|
strFuns :
関数を表す文字列 |
|
my_str2Fun: 文字列から関数へのマッピング関数 |
|
delimiter : strFunsの区切り文字 |
|
例)%f%d%s%n → Array(f, d, s, n) |
|
Public Function splitStr2Funs(ByVal strFuns As String, _ |
|
ByRef my_str2Fun As Variant, _ |
|
ByVal delimiter As String) As Variant |
| 戻る |
|
|
|
partition_points
によるGROUP-BY |
|
matrix
: 対象配列(2次元配列またはジャグ配列) |
|
pp :
partition_points (集計する行範囲を区切る行番号の集合) |
|
strFuns :
列ごとの集計関数を表す文字列 |
|
my_str2Fun: 文字列から集計関数へのマッピング関数(str2SummaryFunがデフォルト) |
|
例)group_by_partition_points(matrix, pp,
"%t%c%s%a%min%max") |
|
Public Function group_by_partition_points(ByRef matrix As Variant, _ |
|
ByRef pp As Variant, _ |
|
ByRef strFuns As String, _ |
|
Optional ByVal my_str2Fun As Variant) As Variant |
|
|
|
printM m |
|
|
|
|
|
|
|
|
|
| 戻る |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
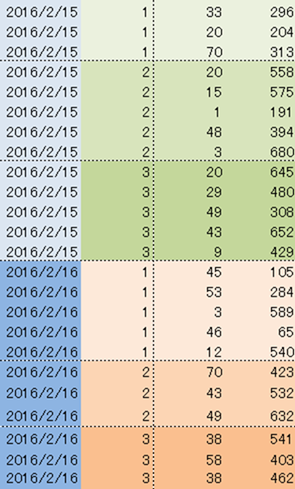
pp = partition_points_pred(zipC(subM(m, , Array(0, 1))),
p_less_dic) ← 左2列で区分化 |
|
printM pp |
|
0 3
8 13 18 21 24
← 区切り位置 |
| 戻る |
summary = group_by_partition_points(m, pp, "%t%t%s%a") |
|
printM summary |
|
2016/02/15 1 123
271 |
|
2016/02/15 2 87
479.6 |
|
2016/02/15 3 150
502.8 |
|
2016/02/16 1 159
316.6 |
|
2016/02/16 2 162
529 |
|
2016/02/16 3 134 468.666666666667 |
|
↑ ↑ ↑
↑ |
|
top(t)
top(t) 小計(s) 平均(a) |
|
|
csvファイルの1行を配列に分割 |
|
Function csv2Vector(ByRef expr As Variant, Optional ByRef delimiter As Variant) As
Variant |
|
|
2つの1次元配列の共有部分と非共有部分を特定 |
|
Public Function A_overlap_B(ByRef a As Variant, ByRef b As Variant, Optional ByRef comp As
Variant) As Variant |
|
|
| 戻る |
a =
uniform_int_dist(20, 0, 20):
permutate a, sortIndex(a)
' [ 0〜20] の範囲の昇順整数 |
|
b =
uniform_int_dist(20, 10, 30): permutate b, sortIndex(b) '
[10〜30] の範囲の昇順整数 |
|
' 重なり合った部分を特定する |
|
x =
A_overlap_B(a, b)
' <- Jag配列 |
|
' ----------------------------------- |
|
printM
catR(a, x(0))
' 上段:a自身 下段:bと重なっている部分 |
|
0 0
1 4 5
5 5 6
9 10 10 13 13 15 15 15 16 17 17 19 |
|
0 0
0 0 0
0 0 0
0 0 0 1 1 1 1 1 1 1 1 1 |
|
----------------------------------- |
|
printM
catR(b, x(1)) '
上段:b自身 下段:aと重なっている部分 |
|
12 13 13 14 15 16 16 17 18 19 21 22 22 23 23 24 26 26 28 30 |
|
0 1 1 0 1 1 1 1 0 1 0 0 0 0 0 0 0 0 0 0 |
|
|
|
|
|
|
|